





每经记者:宋欣悦 每经编辑:高涵

照片源自:视觉中国
近期,中国AI初创机构深度求索(DeepSeek)在全世界掀起波涛,硅谷巨头恐慌,华尔街焦虑。
短短一月内,DeepSeek-V3和DeepSeek-R1两款大模型相继推出,其成本与动辄数亿乃至上百亿美元的国外大模型项目相比堪叫作优惠,而性能与国外顶尖模型相当。
做为“AI界的拼多多”,DeepSeek还动摇了英伟达的“算力信仰”,旗下模型DeepSeek-V3仅运用2048块英伟达H800 GPU,在短短两个月内训练完成。除了性价比超高,DeepSeek得到如此高的关注度,还有另一个原由——开源。DeepSeek彻底打破了以往大型语言模型被少许机构垄断的局面。
被誉为“深度学习三巨头”之一的杨立昆(Yann LeCun)在社交平台X上暗示,这不是中国追赶美国的问题,而是开源追赶闭源的问题。OpenAI首席执行官萨姆·奥尔特曼(Sam Altman)则罕见地表态叫作,OpenAI在开源AI软件方面“始终站在历史的错误一边”。
DeepSeek拥有那些创新之处?DeepSeek的开源策略对行业有何影响?算力与硬件的主导地位是不是会逐步被削弱?
针对以上疑问,《每日经济资讯》记者(以下简叫作NBD)专访了复旦大学计算机学院副教授、博士生导师郑骁庆。他认为,DeepSeek在工程优化方面取得了明显成果,尤其是在降低训练和推理成本方面。“在业界存在着两个法则,一个是规模法则(Scaling Law),另一一个法则指的是,随着技术的持续发展,在既有技术基本上连续改进,能够大幅降低成本。”
针对DeepSeek选取的开源策略,郑骁庆指出,“开源模型能够吸引全世界顶尖人才进行优化,对模型的更新和迭代有加速功效。”另外,开源模型的透明性有助于消除运用安全的顾虑,促进全世界范围内人工智能技术的公平应用。
尽管DeepSeek的模型降低了算力需要,但郑骁庆强调,AI模型仍需要必定的硬件基本来支持大规模训练和推理。另外,大规模数据中心和预训练仍是AI发展的重要构成部分,但将来可能会更注重高质量数据的微调和强化学习。

郑骁庆 照片源自:受访者供图
规模法则之外,还有另一个法则
NBD:微软CEO萨提亚·纳德拉在微软2024年第四季度财报tel会上说到,DeepSeek“有有些真正的创新”。在您看来,DeepSeek有那些创新点呢?
郑骁庆:在深入研读DeepSeek的技术报告后,咱们发掘,DeepSeek在降低模型训练和推理成本方面采用的办法,大多基于业界已有的技术探索。例如,键值缓存(Key-Value cache)管理,对缓存数据进行压缩。另一个是混合专家模型(MoE,Mixture of Experts),实质上指的是,在推理的时候,只需运用模型的某一个特定的模块,而不需要所有模型的网络结构和参数都参与这个推理过程。
另外,Deepseek还采用了FP8混合精度训练的技术手段。这些其实之前都有所探索,而DeepSeek的创新之处就在于,很好地将这些能够降低技术和推理成本的技术整合起来。
NBD:您认为DeepSeek现周期的技术水平上是不是已然接近或达到了全世界领先水平呢?
郑骁庆:DeepSeek日前在现有技术基本上,包含网络结构训练算法方面,实现了一种阶段性的改进,并非是一种本质上的颠覆性创新,这一点是比较知道的。其改进重点是针对特定任务,例如,DeepSeek在数学、代码处理以及推理任务等方面,提出了一种在性能与成本上相对平衡的处理方法。然而,它在开放行业(open domain)上的表现,优良并不是非常显著。
在业界存在着两个法则,一个是规模法则(Scaling Law),即模型的参数规模越大、训练数据越多,模型就会更好。另一一个法则指的是,随着技术的持续发展,在既有技术基本上连续改进,能够大幅降低成本。
例如说,以GPT-3为例,初期它的成本就很高。但随着科研的深入,科研人员逐步清楚那些东西是工作的,那些东西是不工作的。科研人员基于过往的成功经验,科研目的会逐步清晰,成本实质上亦会随之降低。
DeepSeek的成功,我更觉得可能是工程优化上的成功。当然亦非常高兴看到中国的科技企业在大模型的时代,在性能与成本的平衡方面取得了明显发展,持续推动大模型的运用和训练成本下降。符合刚才我说到的第二个法则的状况之下,步行到世界前列。
DeepSeek有效平衡性能和成本,但对芯片需要影响不大
NBD:DeepSeek旗下模型的最大亮点之一是在训练和推理过程中明显降低了算力需要。您认为这种低成本大效能的技术创新,长时间来看,会对英伟达等芯片机构产生什么影响呢?
郑骁庆:我个人认为,它并不会对芯片采购量或出货量产生太大的影响。
首要,像DeepSeek或类似的机构,在寻找有效的整合处理方法时,需要进行海量的前期科研与消融实验。所说的消融实验,即指经过一系列测试来确定哪个方法是有效的以及那些方法的整合是有效的。而这些测试就非常依赖于芯片,由于芯片越多,迭代次数就越多,就越容易晓得哪个东西工作或哪个东西不工作。
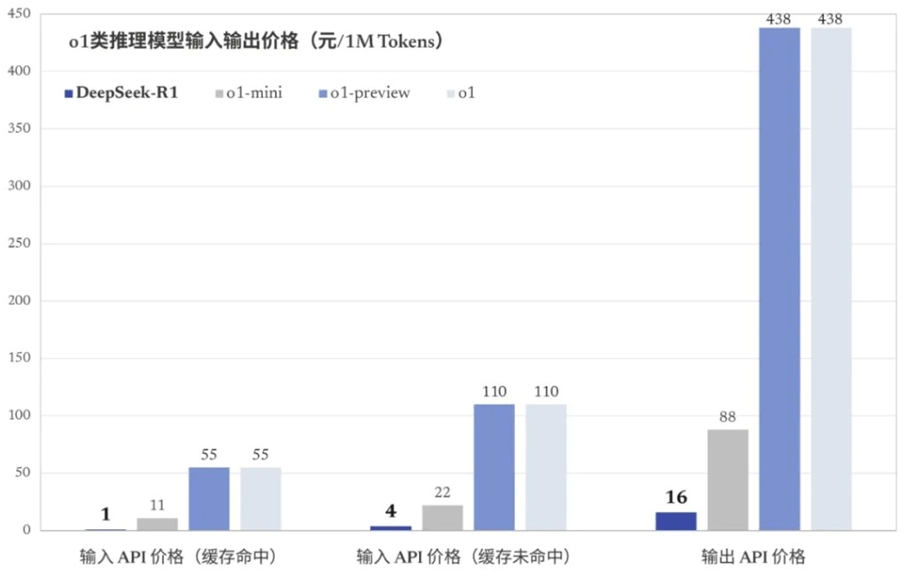
例如说,DeepSeek的训练预算不到600万美元。它的技术报告中说到,不到600万美元的资金,是根据GPU的小时数(每小时两美元)来估算的。亦便是说,她们基于之前的非常多科研,把整条训练流程都已然搞清楚的状况之下(那些是工作,那些不工作的),重新走一遍。它的GPU的运算速度是多少,运算小时数是多少,而后再乘以每小时两美元得到的这个结果。报告中亦说到了,600万美元其实无包括先期科研成本,例如,在结构上的探索、在算法上的探索、在数据上采收集上的探索的成本,亦无涵盖消融实验的开销以及设备的折旧费。因此,我个人判断,对英伟达其实影响不是那样大。
另一,DeepSeek的科研显示,非常多中小企业都能用得起这般的大模型。尽管训练成本的下降可能会暂时减少对GPU的需要,但大模型变得更加经济,会使本来由于模型成本太高而不打算运用大模型的企业,加入到运用模型的行列,反而会增多针对芯片的需要。
NBD:随着DeepSeek-V3、R1等低成本大模型的面世,传统的大规模数据中心和高投入的大模型训练是不是仍然值得继续推进呢?
郑骁庆:我觉得仍然值得。由于首要DeepSeek模型是语言模型,还无扩展到多模态,乃至于咱们以后要科研世界模型。那样一旦引入多模态之后,对算力的需求和基本设备需求就会成指数的增长。由于人工智能不可能仅仅局限于语言体本身,语言只是智慧的一种表现,而在这方面的探索仍然需要这般的一个基本设备。
刚才亦说到DeepSeek其实是在非常多先期研究的基本之上,找到了一条性能和成本平衡的一个处理方法。先期科研包含各样各样的尝试,怎么样去加速它呢?这个还是需要强大的硬件支持。否则,每迭代一次,就可能需要长达一年多的时间,这显然是没法赶上此刻AI军备竞赛的。而倘若有几万张卡,迭代可能几天就完成为了。
另一便是应用方面。即便是模型的推理成本再低,当需要支持数千、数万乃至更大规模的并发运用时,仍然需要一个配备海量显卡的强大基本架构来保证稳定运行。
我觉得大规模预训练这一波潮流可能会弱化,可能不会作为下一步大众争夺的主战场。之前这个行业曾是竞争激烈的战场,但此刻看来,成本和产出之间的比例正逐步趋于紧缩。然则后面两步——高质量数据的微调和基于强化学习的人类偏好对齐,我相信将来会有更加多的投入。

照片源自:视觉中国
开源加速模型更新和迭代,降低安全顾虑
NBD:DeepSeek采用开源模式,与许多国外大模型巨头闭源的做法区别。您怎么看开源模型在推动AI行业发展中的功效?
郑骁庆:DeepSeek日前受到了广泛地关注和认可。从开源模型与闭源模型的方向来看,咱们观察到,开源模型在累积了以往科研成果的基本上,在目的知道的状况之下,借助于各样训练技巧以及模型结构上的优化,尤其是吸收先前科研者在大模型行业已验证有效的原理和办法,开源模型已能够大致追上闭源模型。
开源模型最大的好处就在于,一旦模型开源,全世界的顶尖人才都能基于这些代码进行进一步的迭代与优化,这无疑加速了这个模型的更新与发展进程。相比之下,闭源模型肯定是无这般的能力的,只能靠持有这个闭源模型所属公司的内部人才去推动模型的迭代,迭代速度相对受限。
另一,开源模型透明开放,亦缓解了公众针对大模型运用安全的有些顾虑。倘若模型闭源,大众在运用过程其中可能或多或少会有有些顾虑。况且开源模型针对人工智能的普及以及全世界范围内的公平应用起到了非常好的促进功效,尤其是技术平权方面。亦便是说,当一项科学技术发展起来以后,全世界的人,不管来自哪个国家、身处何地,都应用享有平等地享受这种技术所带来的优良及其产生的经济效益。
此刻的AI竞争是在中国的中国人和在美国的中国人竞争
NBD:DeepSeek团队成员多为国内顶尖高校的应届毕业生、在校博士生。您认为中国AI是不是存在独特的竞争优良?
郑骁庆:我觉得咱们的AI上面的竞争优良,其实是咱们的人才数量上的优良。这几年,从我个人来看,咱们的高等教育,包含硕士、博士的培养,有了长足进步。此刻从中国的头部高校来看,对博士生、硕士生的培养已然比较接近于美国。
在这般的状况之下,咱们的基本高等教育质量的提高,使得咱们贮存了海量的人才。在这般的过程其中,咱们能够对现有的技术进行快速的消化。
实质上,美国许多大模型科研团队,不乏有华人的身影。大众开玩笑说,此刻的人工智能竞争是在中国的中国人和在美国的中国人竞争。要说劣势,其实我觉得还是很遗憾的,那便是咱们很少能有颠覆性的创新。
